

The data ecosystem is flawed. Fixing it requires hard work to overcome many barriers. Data Basis has done exactly that to build a public good that puts data in people’s hands.
Why data?
Data is a critical input to a variety of activities. Governments use it to guide public policy. Researchers use it to describe reality and to test theories with statistical analyses. Companies use it to track markets, to inform business decisions, and to innovate over new products. Journalists use it for fact checking, to uncover new stories. Non-profits use it to design reform agendas.
In summary, users (i.e. decision-makers, researchers, journalists) need data to answer questions (e.g. “how did the economy perform last year?”, “what neighbourhood should receive government transfers?”, “what model can better predict the weather?”) and to make decisions.
The data ecosystem is flawed
Yet, accessing data in a state ready for analysis is often tremendously costly, if not outright impossible: as illustrated in Figure 1, the distance between a question and an answer can be long. And searching for data online is not easy. Users often do not know exactly what dataset they need, what datasets exist, or who exactly provides them. Government websites have low-quality unreliable layouts that make finding data difficult. Online addresses change frequently and little or no useful metadata is provided. When metadata does exist, it is often incomplete, outdated, or wrong. Auxiliary files, such as dictionaries, tutorials, or reports, are often confusing, outdated, difficult to parse, or absent altogether.
Figure 1: The journey from question to answer
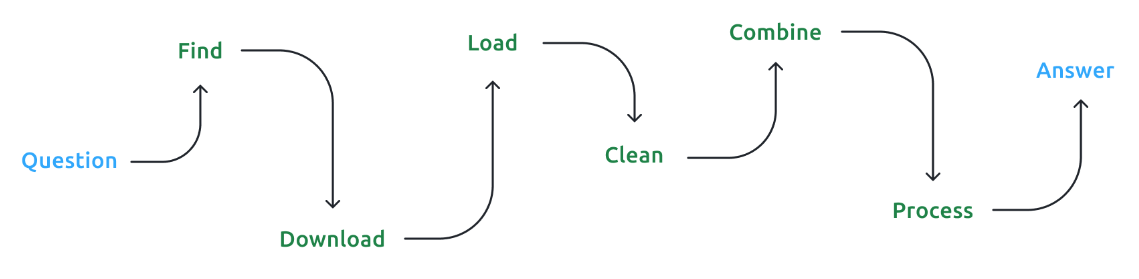
Even conditional on finding the data one needs, other important challenges still remain. Downloading data can be difficult when files are large or when providers’ servers are slow and unstable. Loading data locally can be costly when it comes divided in dozens or hundreds of files in archaic formats, or when its total size is larger than one’s local RAM memory. Most importantly, users still need to clean the data, which can require months of work. Each user repeats the same process, each time with new bugs being introduced to the code.
Despite the progress observed in recent years, the data access scenario worldwide is still dire. And there are understandable reasons behind this situation: there is virtually no institution with both the incentives and the technical and organisational capabilities to provide high-quality data at scale to the public. First, data is a public good whose provision generates substantial positive externalities. As is well understood by economists, this implies that its market provision will be sub-optimal. Companies collecting and organising it will charge for access; researchers have no career incentives to release and maintain data. Second, for the entities with incentives aligned to social welfare, such as governments and non-profits, there are enormous technical, organisational, and political challenges to high-quality data provision. Technological capabilities are low on average. Data is produced in vast amounts by a variety of agencies which often do not communicate or are unwilling to share. Turnover of staff makes public data provision extremely unstable. For example, decisions of what data to collect and provide, how to name files, or even what platform to use, change every few years.
This is why we created and maintain the Data Basis project, which simultaneously solves all problems listed above and, thus, attempts to reduce the distance between users’ questions and answers to zero. Data Basis is a non-profit organisation founded in 2019 in Brazil with the mission to universalise access to high-quality data. We aim to promote economic development and social welfare by supporting evidence-based policy making, science, and rational discourse. The organisation exists at the intersection of four communities: modern open-source software development, data science, academic research, and policymaking.
We develop three core products that help us take data access to an unprecedented level of quality and scope: a search engine, a data lake, and APIs in various programming languages. Our platform and search engine allows users to quickly find the data they need. The unified schema and filters powering it make searching for datasets easy. Our data lake provides users access to hundreds of structured, normalised, and up-to-date tables. Data is readily available for joins, aggregations, selections, and analysis in general. Users can query data at scale for free without ever having to download files locally. Lastly, we provide APIs in Python and R that make accessing data a matter of two or three lines of code. All our software is open-source on GitHub.
Reflections from building Data Basis: Risks, challenges and lessons
Creating Data Basis has been a rewarding but also deeply challenging journey. Here are some reflections from our experience:
The importance, and difficulty, of maintaining users’ trust in our platform
From the beginning we knew that acquiring and maintaining users’ trust in the data we provide is crucial. That meant doing everything right: keeping high-quality metadata, fixing data cleaning errors quickly, keeping all data up to date with minimal delays, nurturing a community via open communication, and a lot more. We understood early the responsibility we’d hold once users start using our data without even double checking the original sources.
Sustainability matters: funding, incentives, and the hybrid model
As a non-profit NGO, we rely on a hybrid model: offering data access as a public good while generating revenues through subscriptions, consulting, training, and data-engineering services. This trade-off is necessary if we want the organisation to thrive – but it also creates tensions: how to balance open-access commitment with financial sustainability; how to keep incentives aligned; how to avoid “privatising” access even though the mission is public.
Community and collaboration are essential
Data Basis has benefited enormously from volunteers, researchers, civil-society partners – people who contribute paperwork, flag errors, help maintain tables, give feedback. Without a community, the platform would just be a static archive – but with it, it becomes a living ecosystem of knowledge, use, and improvement.
Reward comes when data sparks real-world impact
The most satisfying moments are when we see a research paper, a policy brief, a journalistic investigation, or a government report that cites Data Basis and builds on our cleaned data – especially when that work influences public debate, resource allocation, social programmes or transparency.
Final thoughts: Data Basis as part of a broader open-data ecosystem
The story of Data Basis is not just about building a big data warehouse. It is part of a broader movement for open data, transparency and evidence-based public debate. We take huge inspiration from other open data projects, such as IPUMS, the SHRUG, Our World in Data, Opportunity Insights, the World Bank Microdata Library, MapBiomas, and many more. All these help change the notion of what data can be: not a proprietary asset, but a shared infrastructure, a public good.
As the community of researchers, policymakers, civil society organisations, and citizens becomes more data-literate, the demand for reliable, accessible, documented and interoperable data will only grow. We hope that Data Basis can contribute to meet that demand, and help show what is possible when we treat data as public infrastructure.
If you are a researcher, journalist, policymaker, or just someone curious – I invite you to explore the platform, use the data, and join us in building a data-rich public sphere.