


Agricultural productivity in developing countries remains low and uneven, with high-return crops offering significant potential gains but limited adoption due to clustered social networks that restrict the diffusion of new technologies.
In many developing countries, agricultural productivity remains both central to livelihoods and puzzlingly inefficient. Productivity is not only low on average (Gollin et al. 2014a, Gollin et al. 2014b), but measured productivity is also highly unequal across farms (Gollin and Udry 2021, Adamopoulos et al. 2022, Chen et al. 2022). Policies that are specifically targeting agricultural productivity may thus be instrumental in raising the living standards of developing economies. Indeed, changes in agricultural production are now mostly explained by changes in agricultural productivity (better seed varieties, management practices, factor allocation, crop choice), in the same manner as overall growth is now mostly explained by Total Factor Productivity growth (the well-known ‘Solow residual’) (Figure 1).
Figure 1: The role of productivity in agricultural growth
Source: Ritchie et al. (2023).
A crop productivity gap
Recent research has explored several factors underlying productivity and its variation across farms, such as land market frictions (Adamopoulos and Restuccia 2020) or selection into rural-urban migration (Adamopoulos et al. 2022). In Vietnam – the context of our study – and other developing countries around the world, there is an observable, obvious factor underlying agricultural productivity differences: the portfolio of agricultural commodities.
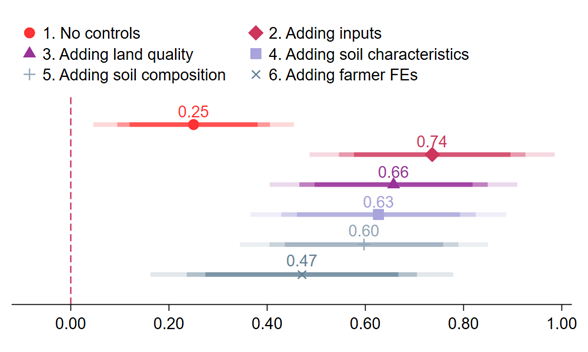
Some crops – such as coffee, cashews, rubber, and peppers – are typically grown on low-quality, rugged land, yet are in high demand in international markets and are much more productive than widely grown staple crops (rice, maize, cassava). We label these crops as ‘high-return crops’ and derive their productivity premium by controlling for inputs (e.g. land, labour, fertilisers, herbicides), land quality, soil characteristics, soil composition, and farmer fixed effects (Figure 2). In our most involved specification, controlling for farmer’s unobserved ability, this premium is 0.47, which corresponds to a premium of around 60%. Given this premium, a natural question arises: why are households primarily using land for purposes other than growing high-return crops?
Figure 2: The crop productivity gap
The role of social networks in crop adoption
Economists have long documented that farmers learn from each other when adopting new technologies and high-return agricultural practices (Foster and Rosenzweig 1995, Bandiera and Rasul 2006, Conley and Udry 2010, Duflo et al. 2011, Suri 2011, Kala 2017, Beaman and Dillon 2018, Banerjee et al. 2019, de Janvry et al. 2025). In our research (Groeger and Zylberberg 2025), we are most interested in understanding the role of networks in explaining the lack of high-return crop adoption: Why have tight-knit social networks in rural Vietnam not led to high adoption rates?
Answering this question requires addressing two empirical challenges: (i) observing entire social networks, and (ii) identifying learning through networks. The novelty of our approach is to conduct a census of four rural villages in the Central Highlands of Vietnam in 2019 and 2022, allowing us to reconstruct the closed, dynamic social structure within each village. The nature of village formation – through staggered population resettlement – allows us to isolate variation in network formation: the exact timing of arrival across settlers strongly predicts home locations within the few streets that compose each village, and home proximity markedly increases the likelihood of forming a link. The probability for a link to exist between any two households of a village is 0.016; this probability, however, rises to 0.05 for households living in very close proximity (within 100 meters, see Figure 3).
Figure 3: Proximity and network linkages
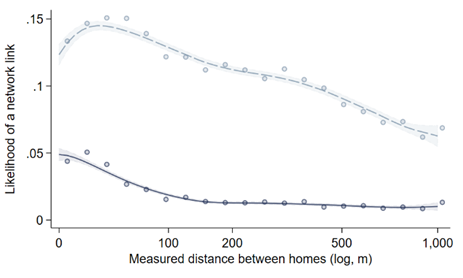
Note: First-order links in darker blue.
Figure 4: Home proximity and possible confounders (balance test)
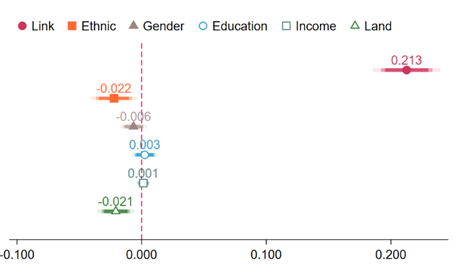
One concern with using home proximity as a predictor for network linkages is that omitted household attributes may influence the selection of other households in their vicinity: a successful family may attract other ambitious families, thereby falsely attributing neighbours’ economic outcomes to proximity rather than underlying household characteristics. Two observations support our strategy:
- Settlement-induced ties – living close to each other – are typically less directly affected by agricultural practices than work-based ties – farming close to each other.
- Our villages were part of resettlement programmes spanning around 30 years, and new settlers would typically be given or claim a land plot for residential purposes upon arrival: the geography of residential settlement strongly reflects the timing of arrival to the Central Highlands.
A corollary is that home settlement patterns do not induce obvious similarities in given household characteristics, e.g. educational attainment or belonging to similar ethnic minorities (Figure 4).
Integrating this predictor for social linkages into a shift-share design, we show that exposure to high-return crop adoption through the social network does predict future adoption: an additional standard deviation (SD) in exposure – equivalent to the gap between households who have no direct contacts growing high-return crops and households who only have one contact growing such crops – increases the likelihood of growing a high-return crop by around 8 to 10 percentage points. This presents an apparent contradiction: despite a large network multiplier, the overall adoption of high-return crops remains low, with high-return crops being grown on approximately one-fifth of agricultural land parcels in 2019.
The limits of clustered networks
How do we reconcile a sizable network multiplier with the limited diffusion of high-productivity agricultural practices? We show that it relates to the network structure through (i) a static argument and (ii) a dynamic argument. First, we show that a large network multiplier may coexist with a relatively low, but non-negligible, adoption rate when social networks display large homogeneity (i.e. connected pairs have similar agricultural practices). Indeed, network connections are primarily formed by family links or work practices: a node that is connected to treated nodes is likely to be treated already; reciprocally, a non-treated node is unlikely to be exposed to the treatment through the network. Thus, randomising network formation for households arriving in our villages would have markedly increased crop adoption (Figure 5, simulating past high-return crop adoption in re-sampled, random social networks).
Figure 5: Network structure and the propagation of treatment – randomising past networks
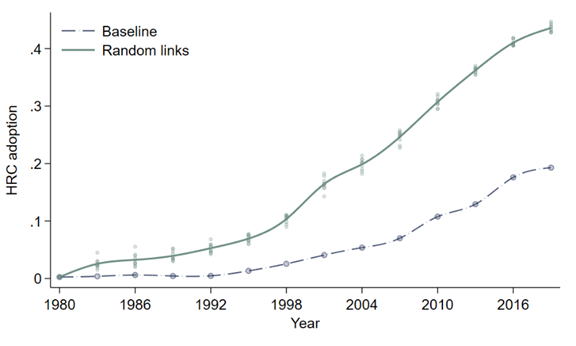
Second, even when the initial allocation of treatment is random, networks are highly clustered and such clustering structure implies that the treatment will primarily diffuse within localised clusters, thereby inducing a high degree of similarity in agricultural practices over time. To shed light on this decreasing return to social multipliers, we randomise the distribution of agricultural practices and/or the network structure. Though both would generate a much higher adoption rate after 50 years, these experiments markedly differ in their dynamic impact: a random network does not generate decreasing returns over time, while a randomised treatment would generate homogeneity and decreasing returns in the longer run, through propagation within clustered networks.
Policy implications: Leveraging social networks for effective agricultural policy
We conclude with a discussion of policy implications and how to target the most relevant households with respect to their network position (e.g. Banerjee et al. 2013, Kim et al. 2015, Banerjee et al. 2019, Beaman et al. 2021, Akbarpour et al. 2025, Sadler 2025, Bramoulle and Genicot 2024). A planner randomising initial seeds may want to allocate treatment to ‘inbetweeners’ – those who connect different clusters of farmers – ensuring that the returns to social links do not decrease with time. More ambitiously, policies that create opportunities for farmers to connect outside their usual kinship or work groups – for instance, through training sessions, cooperatives, or agricultural extension programmes – could help overcome the bottlenecks created by clustered networks.
References
Adamopoulos, T, and D Restuccia (2020), “Land reform and productivity: A quantitative analysis with micro data,” American Economic Journal: Macroeconomics 12(3): 1–39.
Adamopoulos, T, L Brandt, J Leight, and D Restuccia (2022), “Misallocation, selection, and productivity: A quantitative analysis with panel data from China,” Econometrica 90(3): 1261–1282.
Akbarpour, M, S Malladi, and A Saberi (2025), “Just a few seeds more: The value of network information for diffusion,” American Economic Review, forthcoming.
Bandiera, O, and I Rasul (2006), “Social networks and technology adoption in northern Mozambique,” Economic Journal 116(514): 869–902.
Banerjee, A, A G Chandrasekhar, E Duflo, and M O Jackson (2013), “The diffusion of microfinance,” Science 341(6144): 1236498.
Banerjee, A, A G Chandrasekhar, E Duflo, and M O Jackson (2019), “Using gossips to spread information: Theory and evidence from two randomized controlled trials,” Review of Economic Studies 86(6): 2453–2490.
Beaman, L, and A Dillon (2018), “Diffusion of agricultural information within social networks: Evidence on gender inequalities from Mali,” Journal of Development Economics 133: 147–161.
Beaman, L, A BenYishay, J Magruder, and A M Mobarak (2021), “Can network theory-based targeting increase technology adoption?,” American Economic Review 111(6): 1918–43.
Bramoulle, Y, and G Genicot (2024), “Diffusion and targeting centrality,” Journal of Economic Theory 222: 105920.
Chen, C, D Restuccia, and R Santaeulalia-Llopis (2022), “The effects of land markets on resource allocation and agricultural productivity,” Review of Economic Dynamics 45.
Conley, T G, and C R Udry (2010), “Learning about a new technology: Pineapple in Ghana,” American Economic Review 100(1): 35–69.
de Janvry, A, M Rao, and E Sadoulet (2025), “Seeding the seeds: Role of social structure in agricultural technology diffusion,” Journal of Economic Behaviour & Organization 236: 107088.
Duflo, E, M Kremer, and J Robinson (2011), “Nudging farmers to use fertilizer: Theory and experimental evidence from Kenya,” American Economic Review 101(6): 2350–90.
Foster, A D, and M R Rosenzweig (1995), “Learning by doing and learning from others: Human capital and technical change in agriculture,” Journal of Political Economy 103(6): 1176–1209.
Gollin, D, and C Udry (2021), “Heterogeneity, measurement error, and misallocation: Evidence from African agriculture,” Journal of Political Economy 129(1): 1–80.
Gollin, D, D Lagakos, and M E Waugh (2014a), “Agricultural productivity differences across countries,” American Economic Review 104(5): 165–70.
Gollin, D, D Lagakos, and M E Waugh (2014b), “The agricultural productivity gap,” Quarterly Journal of Economics 129(2): 939–993.
Groeger, A, and Y Zylberberg (2025), “The pick of the crop: Agricultural practices and clustered networks in village economies,” Journal of the European Economic Association, jvaf028.
Kala, N (2017), “Learning, adaptation, and climate uncertainty: Evidence from Indian agriculture.”
Kim, D A, A R Hwong, D Stafford, D A Hughes, A J O’Malley, J H Fowler, and N A Christakis (2015), “Social network targeting to maximise population behaviour change: A cluster randomised controlled trial,” The Lancet 386(9989): 145–153.
Ritchie, H, P Rosado, and M Roser (2023), “Agricultural production,” Our World in Data.
Sadler, E (2025), “Seeding a simple contagion,” Econometrica 93(1): 71–93.
Suri, T (2011), “Selection and comparative advantage in technology adoption,” Econometrica 79(1): 159–209.